

نویسنده: مکس تگمارک
مترجم: میثم محمدامینی
انتشارات: نشر نو

همیشه وقتی وارد آن کتابفروشی کنج خیابان میشدم، انگار از زمین خودمان کنده شده بودم و به سرزمین عجایب پا گذاشته بودم: کتابها و گلها. همه جا بودند. کتابهایی که هر کدام جهانی دیگر برایم خلق میکردند. خیلی جای دنجی بود. جایی که رفتن به آنجا همیشه حالم را خوب میکرد. گلها و گلدانها در هر قفسه بودند. گیاههای روندهای که کنار قفسههای کتاب را کامل میپوشاندند. باد خنکی که میوزید و عطر کاغذ و عود و گیاه را بلند میکرد. اما این بین، کتابفروش، اصلا چیز دیگری بود! انگار تمام کتابها در دستش مثل موم بودند! کتابخوان حرفهای بود و مرا هم خوب میشناخت. آنجا میرفتم و به من کتاب بعدی را توصیه میکرد و حقا که توصیههایش دقیق بود! «دفعه قبلی آن کتاب را خریدی. این را این بار ببر.» و دقیقا میزد در خال!
طاقچه را «نزدیکترین کتابفروشی شهر» مینامیم و معتقدیم باید لذت کتاب خواندن را با تمام کاربرانمان به اشتراک بگذاریم. در این میان، سلیقه کاربران از همه چیز برایمان اهمیت بیشتری دارد و تلاشمان را میکنیم که آنچه شما را خوشحال میکند فراهم کنیم. در این یادداشت، از سیستم جدید پیشنهاددهندهمان میگوییم و آرزوهای بلندپروازانهای که دنبال میکنیم.
وقتی با حجم زیاد و رو به رشدی از انتخابها مواجه میشویم، آزادی و کنترل بیشتری داریم و میتوانیم تصمیم بگیریم چه چیزی را انتخاب کنیم. اما وقتی هنگام تصمیمگیری میشود، شاید انتخاب برایمان سختتر شود. بین کلی گزینه خوب کدام را باید انتخاب کنم؟ گاهی این انتخاب صرفا بر اساس منطق است: خوب و خوبتر. اما گاهی سلیقه و حال و هوا هم مطرح است. «من» کدام را باید انتخاب کنم؟!
سامانههای توصیهگر (Recommender Systems)، سامانههایی هستند که به عنوان راهحلی برای این مساله معرفی میشوند. این سامانهها مناسبترین انتخاب را برای کاربران به صورت «شخصی» ایجاد میکنند.
«گلدون» نام سامانه شخصیسازی طاقچه است که با سامانه توصیهگر قدرتمندی به عنوان هسته مرکزی شروع به کار کرد. پروژههای درونی ما در طاقچه نیز اسم و شخصیت دارند!
هنگام ایجاد آن را به چند دلیل «گلدون» نامیدیم:
در بازخوردهای اولیهای که دریافت کردیم، دقت و کارایی سامانه «گلدون» مشخص شد. اما شاید برایتان سوال شده باشد که چطور کار میکند؟
ابتدا لازم بود که سری به کتابخانه «هاگوارتز» بزنیم که اگر جلد اول هری پاتر را خوانده باشید قطعا با آن آشنا هستید. «وینگاردیوملهویوسا» وردی بود که اول برای بلند کردن و جابهجا کردن اجسام پیدا کردیم و «اَپِرِسیوم» هم طلسمی برای نمایان کردن نوشتههایی که با مرکب نامرئی نوشته شدهاند. کافی بود ابتدا طلسم اول را به کار ببریم و بعد هم طلسم دوم را تا جادو اتفاق بیفتد!
شاید دقت گلدون را دیده باشید و فکر کنید چطور این کار را میکند؟ آیا واقعا جادو و طلسمی در کار است؟! دنیای امروز، دنیای پر از داده و آمار است. حجم دادههایی که رد و بدل میشود آن قدر بالاست که تحلیل آن به صورت شخصی ممکن نیست و نیاز به ابزارهای مشخصی دارد. تصمیمگیری دادهمحور چیزی است که امروزه در جهان به اصلیترین مولفه تصمیمگیری تبدیل شده و تمام شرکتهای به روز تکنولوژی جهان، به سمت ایجاد محصولاتی مبنی بر داده رفته اند. به عنوان شرکتی که به روز بودن و استفاده از جدیدترین تکنولوژیها برایمان اهمیت به سزایی دارد، تصمیم گرفتیم شانس خودمان را در این زمینه امتحان کنیم.
در روش علمی کلاسیک، ابتدا کار را با مشاهده آغاز میکنند. سوالی برایمان مطرح میشود؛ فرضیه ای را در نظر میگیریم و آزمایشی طراحی میکنیم که فرضیه خود را پشتیبانی یا رد کنیم.
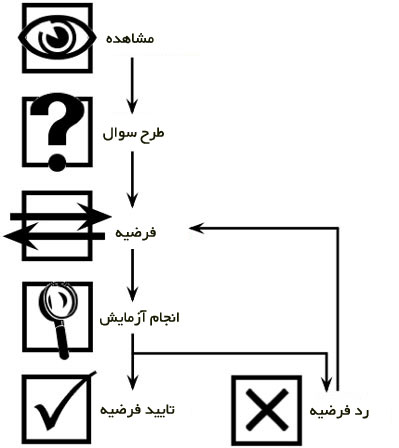
اگر بخواهیم روش علمی را در طراحی محصول به کار بگیریم، به روشهای مبتنی بر داده میرسیم. آنچه امروزه «علم داده» خوانده میشود مجموعهای از روشهای میانرشتهای است که با استفاده از ابزارهای مختلف ریاضی، آمار، مهندسی داده، علوم کامپیوتر، هوش مصنوعی و … سعی بر استخراج دانش و پاسخ به سوالات در زمینه کسب و کارها از میان انبوهی از داده دارند.
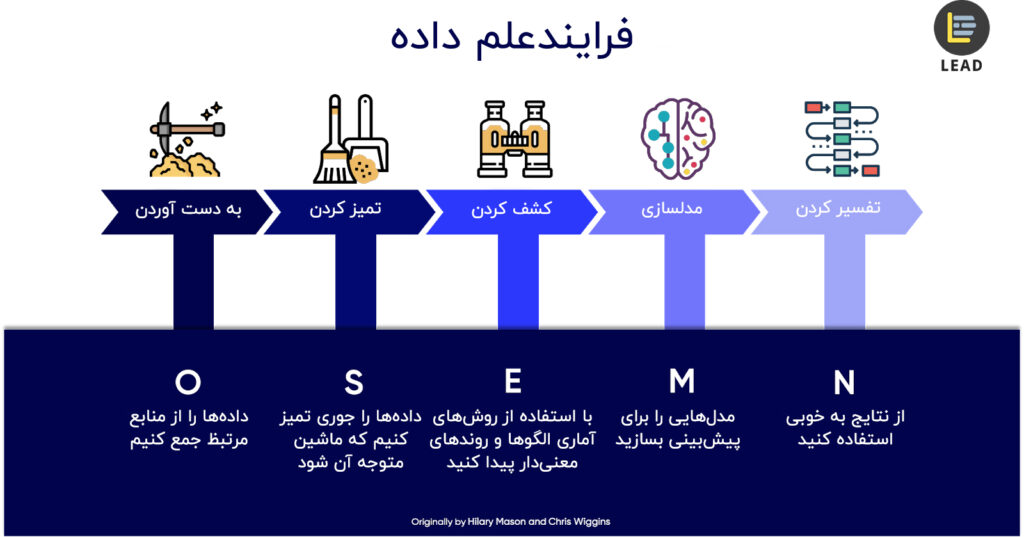
وقتی سوال «چطور به کاربران به سلیقه خاص خودشان -نه سلیقه خودمان- کتاب پیشنهاد بدهیم؟» را مطرح کردیم، در اولین مرحله دادههایی را استخراج کردیم که بتواند به این سوال پاسخ دهند. دادههای استخراج شده لزوما ساختاریافته نیستند و ممکن است از منابع مختلفی جمعآوری شده باشند؛ بنابراین نیاز بود تا روال مهندسی داده روی آنها انجام دهیم تا بتوانیم دادههایی از جنس قابل استفاده داشته باشیم.
پس از «تمیز کردن» دادهها، آنها را بررسی کردیم. دقیقا مثل دانشمندی که نمونههای آزمایشگاهی را در حالات و ابزارهای مختلف زیر ذرهبین قرار میدهد، دادهها را خیلی عمیق زیر ذرهبین قرار دادیم. در تمام این مراحل حفظ حریم شخصی کاربران یکی از مهمترین اصولی بود که لازم بود رعایت کنیم و تمام تلاشمان را کردیم که اطلاعاتی از کاربران درج نکند.
پس از بررسیهای متعدد و آزمایشهای مختلفی که انجام دادیم، دادههای «خرید کاربران» اولین دادههایی بود که تصمیم به استفاده از آنها گرفتیم. حالا زمان آن رسیده بود که برای مسالهمان «مدلی» ارائه کنیم. با استفاده از ابزارهای ریاضی مدلسازی انجام دادیم که بتواند با استفاده از الگوریتمهای پیشرفته و تکنیکهای بهروز ریاضی مسئله ما را حل کند.
«آیا تا حالا واقعیت وجودی خودت رو زیر سوال بردی؟ آیا تا حالا واستادی در مورد کارهات فکر کنی؟ هزینهای که باید بدی اگر حساب و کتابی در کار باشه؟ حساب و کتاب همینجاست.» این دیالوگ «دلوریس» در سریال «وستورلد» است. آیا روزی خواهد رسید که ماشینها به سطحی از ادراک برسند که بتوانند خیالپردازی کنند یا حتی بیشتر، خودآگاه شوند و اختیار خود را به دست بگیرند؟ آیا «شارلوت» میتواند عواطف انسانی را درک کند؟
گاه در فیلمها رباتهای انساننما (اندروید) را میبینیم که توانایی یادگیری همه چیز را دارند. رباتهایی که گاهی حتی از احساس هم برخورداراند. اما «یادگیری ماشین» مساله دورافتاده ای نیست! در حقیقت چیزی است که شاید بارها از آن در جدیدترین تکنولوژیهای ابر قدرتهایی مانند اینستاگرام، گوگل یا اسپاتیفای روزانه استفاده کنیم!
یادگیری ماشین (Machine Learning) و دادهکاوی حوزه ای از هوش مصنوعی است که امروزه تمرکز زیادی از محققان دانشگاهی و کسب و کارها به سمت آن جلب شده است. در واقع میتوان آن را مجموعهای از الگوریتمها و مدلهای آماری و ریاضی دانست که با استفاده از مثالهایی که به عنوان ورودی به آنها میدهیم قادر به شناسایی الگوها و دادن خروجی هستند.
در برنامهنویسی کامپیوتری، ورودی و برنامه را به کامپیوتر میدهیم و پس از محاسبات، نتایج را خروجی میگیریم. اما در یادگیری ماشین، ورودیها و خروجیهای مورد انتظار را به کامپیوتر میدهیم و گویی به کامپیوتر با نشان دادن نمونهها یاد میدهیم که چطور رفتار کند.
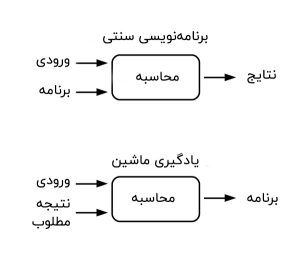

یادگیری ماشین خود به دستههای مختلفی تقسیم میشود که بررسی آنها نیاز به یادداشت تخصصی دیگری دارد اما آنچه در اینجا بیان شد، «یادگیری با نظارت» نامیده میشود. در این نوع یادگیری، ورودیها و خروجیهای مد نظر موجوداند.
روشهای متعددی برای طراحی سیستمهای توصیهگر وجود دارد. به طور عمده میتوان مساله طراحی چنین سیستمی را یک مساله یادگیری ماشین در نظر گرفت. اگر به موضوعات مربوط به هوش مصنوعی علاقهمندید، میتوانید کتاب «زندگی ۳.۰؛ انسانبودن در عصر هوش مصنوعی» را بخوانید.
هرچند انواع مختلفی از چنین سامانههایی وجود دارد اما سیستمهای توصیه گر را میتوان به سه دسته کلی تقسیم کرد. برای توضیح بهتر، سعید و صبا را در نظر بگیرید:
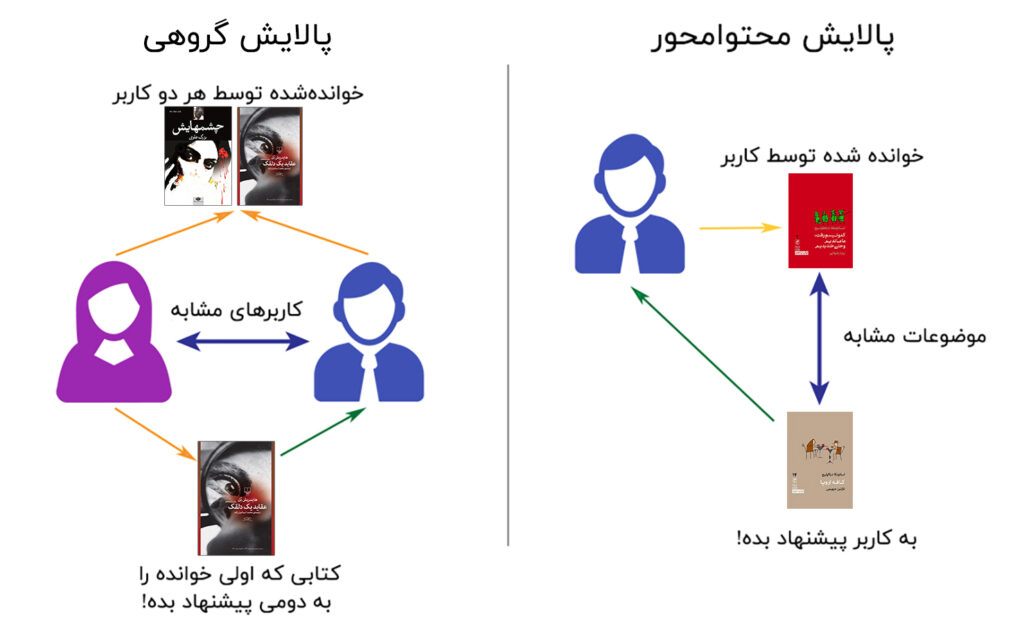
برای آنکه بدانیم کدام مدل جواب بهتری برایمان دارد نیاز بود آزمایشهای متعددی را روی مدلهای مختلف انجام دادیم. در نهایت به دو مدل برای نسخه اولیه رسیدیم که یکی از نوع دوم (پالایش گروهی) بود و یکی از نوع سوم (ترکیبی). این دو مدل را از بین دهها مدلی انتخاب کردیم که طی آزمایشهای متعدد ساختیم و با معیارهای مختلف بررسی کردیم. اما بین این دو مدل تفاوت خیلی کمی از منظر معیارهای سنجش بود. حال وقت آن بود که آنها را در مسابقهای واقعی وارد کنیم.
پیش از مسابقه نهایی لازم بود مدلها بتوانند به طریق بهینهای سرویس دهند. زیرساخت فنی نسبتا مفصلی را برای این پاسخگویی بهینه ایجاد کردیم و بعد زمان فینال فرا رسیده بود…
مسابقه فینال بین سه مدل ریاضی برگزار میشد:
برای مسابقه نهایی از آزمون A/B/n استفاده کردیم. این آزمون زیرمجموعه ای از آزمونهای آماری A/B است و روال آن به این شکل است که مجموعه ای از کاربران را برای آزمون انتخاب میکنیم. سپس کاربران را به سه دسته با توزیع آماری برابر تقسیم میکنیم. باکس اول را در اپلیکیشن طاقچه انتخاب کردیم و تمام ویژگیهای آن اعم از نام، نحوه نمایش و محل را ثابت در نظر گرفتیم. باکس دسته اول کاربران از مدل اول، دسته دوم از مدل دوم و دسته سوم از کتابهای پرفروش یا داغ ترینها نمایش داده میشد. در هر باکس ده کتاب نمایش داده میشد و آزمون را به مدت یک ماه اجرا کردیم.

پس از یک ماه خروجی آزمون را بررسی کردیم. خروجیهای مد نظر نرخ کلیک (CTR) بود. مدل دوم (ترکیبی) با میزان دو برابر برنده مسابقه شده بود. در ضمن کارایی مدل با نسبت دو برابر از حالت پرفروشها مشخص شد.
در آزمون آماری دیگری که انجام دادیم باکس ارائه شده توسط گلدون میزان ۵ برابر نسبت به بقیه باکسها کلیک بیشتری داشت.
نسخه اول گلدون را «گلدون سفید» نامیدیم. باکس اول در اپلیکیشن طاقچه با نام «امروز برای شما» و همچنین باکسهای «دیگران دریافت کردهاند» زیر توضیحات کتابها از خروجیهای اصلی «گلدون سفید» هستند. همچنین در کمپین نوروزی برخی از باکسهای تخفیف برای کاربران مرتب شده بود. «گلدون سفید» برای خروجی دادن نیاز به حداقل تعدادی خرید دارد. اگر هنوز این باکس را دریافت نمیکنید و علاقهمندید پیشنهادهای شخصی دریافت کنید، کتابهای بیشتری بخرید! و در ضمن منتظر نسخههای بعدی گلدون باشید که به زودی امکانات خیلی بیشتری به آن اضافه خواهند شد!

پروژه «گلدون» را که شروع کردیم، از نتایج آن مطمئن نبودیم. سیستمهای توصیهگر هنوز در لبهی علم و تکنولوژی جهان هستند و هر روزه تحقیقات و نتایج زیادی روی آنها ارائه میشود. هرچند که خروجیهای شگفتآور آن در کسب و کارهای غول پیکیری مانند نتفلیکس و اسپاتیفای مشخص است اما هنوز اطمینان نداشتیم. با بلندپروازی زیادی این پروژه را شروع کردیم و خروجی نسخه «گلدون سفید» هم برای خودمان شگفت آور بود و هم بازخوردهایی که از شما دریافت کردیم ما را مصمم به ادامه این راه کرده است.
اما این تازه شروع راه است. گلدون هر روزه در حال بهبود و رشد است. آماده سازی نسخه بعدی گلدون مدتی است که آغاز شده و آرزوها و اهداف خیلی زیادی برای آینده آن داریم. سلیقه کاربرانمان و خوشحالی آنها مهم ترین چیز برایمان است و این بازخوردهای شما هر روز به ما انگیزه میدهد تا جدیدترین و به روزترین تکنیکها را استفاده کنیم تا پیشنهاددهندهی خوبی باشیم.
راستی اگر خواستید بدانید حالا آیا آندروئیدها خواب گوسفندهای الکترونیکی را میبینند یا نه این کتاب را حتما بخوانید و منتظر نسخه بعدی گلدون با نام «گلدون ارغوان» باشید! 🙂
 بستن تبلیغ
بستن تبلیغ
دانلود کتاب از اپلیکیشن طاقچه



